|
Hi everyone! I am Atharva Anand Joshi, Machine Learning Engineer 2 at Hewlett-Packard - Poly. Here, I explore advanced Deep Learning-based techniques for Spatial and Personalized Speech Enhancement on the transmit side of the headset. Our work allows headsets to adapt to the voices of multiple users and over time get better at isolating only their speech in real-time. I am fascinated by the application of machine learning in diverse domains like audio, finance, and marketing. I completed my M.S in Electrical and Computer Engineering with concentration in AI/ML Systems from Carnegie Mellon University. My research spans speech processing, deep learning, and representation learning, and I’ve had the privilege of collaborating with WAVLab under the guidance of Professor Shinji Watanabe. I earned my B.E in Electrical and Electronics Engineering from BITS Pilani in July, 2022. During my undergrad, I worked on research projects under the guidance of Professor Syed Mohammad Zafaruddin (SM Research Group) and Professor Ananthakrishna Chintanpalli. Before joining CMU, I worked as an Analyst at American Express, AI Labs . Here, I explored modelling approaches involving a blend of Tabular deep learning with Tree-based algorithms for Credit Default Prediction - What is the probability of a given customer failing to repay their outstanding debt in near future? This helps in setting the credit line and making other such credit-related decisions. During my internship at AmEx, I developed a template-based framework that allows users to seamlessly create and deploy their end-to-end Self Learning pipelines for Sequence Models. I have also interned at Adobe Research, India with mentors Dr Atanu Sinha and Dr Sunav Choudhary. Here, we created concise user representations which can be projected onto edge server, providing faster marketing services. Feel free to reach out for research collaboration, academic guidance (if you are an undergraduate student from BITS) or even just for a chat! For GRE and TOEFL preparation guidance, especially under time contraints do check out this repository. Email / Resume / Google Scholar / Linkedin / Github |

|
|
|
|
Carnegie Mellon University, Pittsburgh, PA
Master of Science in Electrical and Computer Engineering (December 2024) Concentration: AI/ML Systems GPA: 4.0/4.0 |
|
Birla Institute of Technology and Science, Pilani
B.E. Electrical and Electronics Engineering (July 2022) GPA: 9.49/10 GRE: 331/340 (AWA: 4/6) TOEFL: 109/120 |
|
|
|
HP Inc., Poly Advanced Technology Group
Research and Development February 2025 - Present Summer Internship 2023 and 2024 1) Spatial and Personalized Speech Enhancement on Headsets 2) Poly NoiseBlockAI for Headsets: Deep Learning-based Noise Suppression (Learn more) |
 |
Watanabe’s Audio and Voice (WAV) Lab
Research Collaboration January 2024 - Present 1) Data Scalability Aspects for the Speech Enhancement Task 2) Query-Driven Dynamic Pruning for Large Speech Models 3) ESPnet: End-to-end speech processing toolkit |
|
American Express, Artificial Intelligence Labs
AiDa Deploy Team January 2022 - December 2022 (Intern and Fulltime) 1) Credit Default Prediction through Deep Learning 2) Template-based Development and Deployment on AiDa |
|
Adobe Research, India
Big Data Experience Lab May 2021 - August 2021 Edge Computing for Marketing Technology |
|
[1] M. Someki, S. Bharadwaj, A. A. Joshi, C.J. Lin, J. Tian, J. Jung, M. Müller, N. Susanj, J. Liu, S. Watanabe. Context-Driven Dynamic Pruning for Large Speech Foundation Models. Proc. Interspeech 2025 (Accepted). (Link) [2] A. A. Joshi, H. Settibhaktini and A. Chintanpalli, "Modeling Concurrent Vowel Scores Using the Time Delay Neural Network and Multitask Learning," in IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 30, pp. 2452-2459, 2022, doi: 10.1109/TASLP.2022.3192096. (Link) [3] A. A. Joshi, P. Bhardwaj and S. M. Zafaruddin, "Terahertz Wireless Transmissions with Maximal Ratio Combining over Fluctuating Two-Ray Fading," 2022 IEEE Wireless Communications and Networking Conference (WCNC), 2022, pp. 1575-1580, doi: 10.1109/WCNC51071.2022.9771926. (Link) |
|
S. Chakraborty, S. Choudhary, A. Sinha, S. Nair, M. Ghuhan, Y. Gagneja, A. A. Joshi, A. Tyagi, S. Gupta, “Generating Concise and Common User Representations for Edge Systems from Event Sequence Data Stored on Hub Systems”, US12182829B2, Granted December 31, 2024. (Link) |
|
|
|
Teaching Assistant for 10-605: ML with Large Datasets
Instructors: Prof. Ameet Talwalkar and Prof. Geoff Gordon Course Website: 10-405/10-605 |
|
Teaching Assistant for 18-661: Introduction to Machine Learning for Engineers
Instructors: Prof. Yuejie Chi and Prof. Beidi Chen Course Website: 18-461/18-661 |
|
Teaching Assistant for BITS F312: Neural Networks and Fuzzy Logic
Instructors: Prof. Surekha Bhanot and Prof. Bijoy Krishna Mukherjee Course Website: Team NNFL Here's a presentation on how to read research papers: Demystifying Research Papers |
|
|
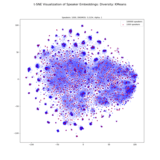 |
Data Scalability Aspects for the Speech Enhancement Task
Investigating large data (>10,000 hours) scalability aspects for the state-of-the-art speech enhancement models. Compared several speaker-level data selection methods using diversity metrics based on speaker embeddings. Extending the work by improving selection methods through non-intrusive speech quality prediction metrics. |
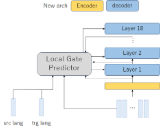 |
Context-Driven Dynamic Pruning for Large Speech Foundation Models
Developed a novel frame-level gate prediction model which can dynamically prune speech LLMs. Studied the impact of several context sources, including speaker characteristics and audio features on the Automatic Speech Recognition and Speech Translation capabilities of the model. Analyzed pruning patterns to understand how the gate predictor decides which modules to prune. Paper |
|
ESPnet: End-to-end speech processing toolkit
Contributed an end-to-end reproducible deep learning pipeline for the Kinect-WSJ dataset – a multichannel, reverberated and noisy version of the WSJ0-2mix dataset. Performed benchmark analysis on this speech separation dataset using current state-of-the-art models. Code / Model |
 |
Proactive Servicing: Guess What? (Amex ML Challenge)
Combined event sequences and demographic data to predict customer intent at the start of the Ask Amex chat session. The approach involved joint training of Bidirectional GRU with Feedforward Networks. Attained a validation top-5 accuracy score of 0.768. Our solution made it to the top 10 leaderboard and was selected for internal presentation. |
 |
High Performance Parallel Implementations for Convolutional Neural Networks
Provided fast OpenMP and CUDA implementations for various subroutines corresponding to the convolution layer. Achieved maximum speedup of 4.23x on the Intel(R) Xeon(R) Silver 4208 CPU and 73.87x on the Nvidia Tesla T4 GPU. Report |
 |
Concurrent Vowel Identification using TDNN-MTL
Predicted the effect of fundamental frequency (F0) difference on the identification scores in a concurrent vowel identification experiment using Deep Learning. From the neuron responses generated by the Auditory Nerve Model, a temporal network architecture was used to model short-term and long-term dependencies. Paper |
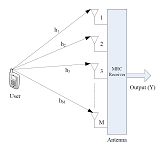 |
Terahertz wireless transmissions with MRC receiver over FTR fading
Framework to perform numerical analysis on FTR channel models obtained upon combining small-scale fading and antenna misalignment effects. This analysis can also be verified using Monte-Carlo Simulations. Code / Paper |
|
I have been an avid practitioner and performer of Hindustani Classical Vocal Music for the past fourteen years.
|
 |
My Instagram Channel
On this channel, I post Classical music, Ghazals and Bollywood covers during my free time. Link |
 |
Ragamalika, the Classical Music and Dance Club of BITS Pilani
Joint Coordinator Composed and performed music for our semester productions: Nritya Ranjani and Sangamam Managed external professional concerts: We've had the opportunity to host some wonderful artists in the past including Pandit Jayateerth Mevundi, Pandit Abhishek Raghuram and IndoSoul by Karthick Iyer. Instagram / Youtube / Facebook |
|
Thanks Jon Barron for this template. |